1Eastern Institute of Technology, Ningbo2Shanghai Jiao Tong University3Peking University 4Carnegie Mellon University5East China Normal University6Ningbo Institute of Digital Twin
✉ Corresponding authors
TL;DR. We build a framework for a humanoid robot to distinguish itself from humans or similar robots through proprioceptive-visual correspondence, without any predefined kinematic model or identity label. This self-other distinction then bootstraps a predictive self-model, enabling various real-world applications.
Distinguishing self from others is a prerequisite for social intelligence, yet humanoid robots that increasingly share workspaces with humans still lack this ability. Here we show that a humanoid robot can learn self-other distinction from proprioceptive-visual correspondence, without any identity labels or kinematic models. Once established, this distinction bootstraps a predictive self-model that maps joint configurations to three-dimensional body occupancy, capturing how the robot's body changes with action. In multi-agent scenes containing humans and morphologically similar robots, the system reliably identifies itself, learns an accurate self-model, and supports downstream tasks including target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
Overview
Distinguishing self from others is a fundamental capability for social intelligence. Before an agent can imitate a demonstrator, coordinate with a partner, or simply avoid colliding with a bystander, it must resolve a prior question: Which body is mine?
Cognitive science points to proprioceptive-visual correspondence as a key mechanism.
We therefore frame self-other distinction as an operational self-instance assignment problem:
From several visible bodies, the robot must select the candidate whose configuration matches its proprioceptive state, without identity labels or prior knowledge of its morphology.
Self-other distinction problem setting
Humanoid robots are entering social environments, where they coexist with humans and morphologically identical peers. To act effectively in such settings, they not only need self-other distinction to identify which body in the scene is itself, but also self-modeling to acquire a predictive representation of that body and how it changes with action.
Self-other distinction
Self-modeling
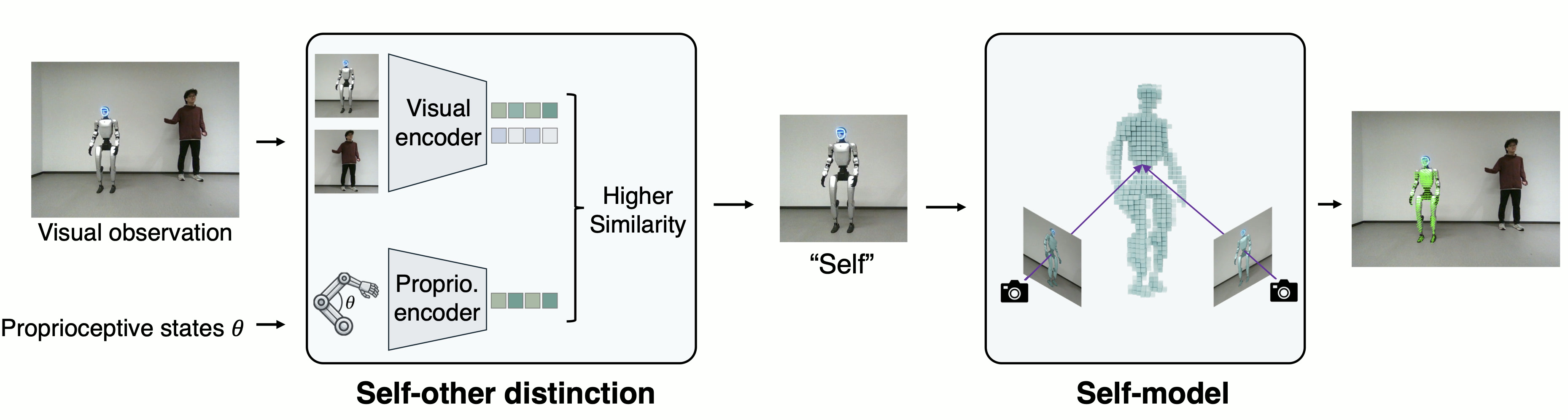
From only proprioceptive states and visual observations, and without any predefined kinematic model or identity label, our framework achieves robust self-other distinction, learns a self-model that predicts 3D body occupancy, and supports downstream tasks including target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
Pipeline overview
Results
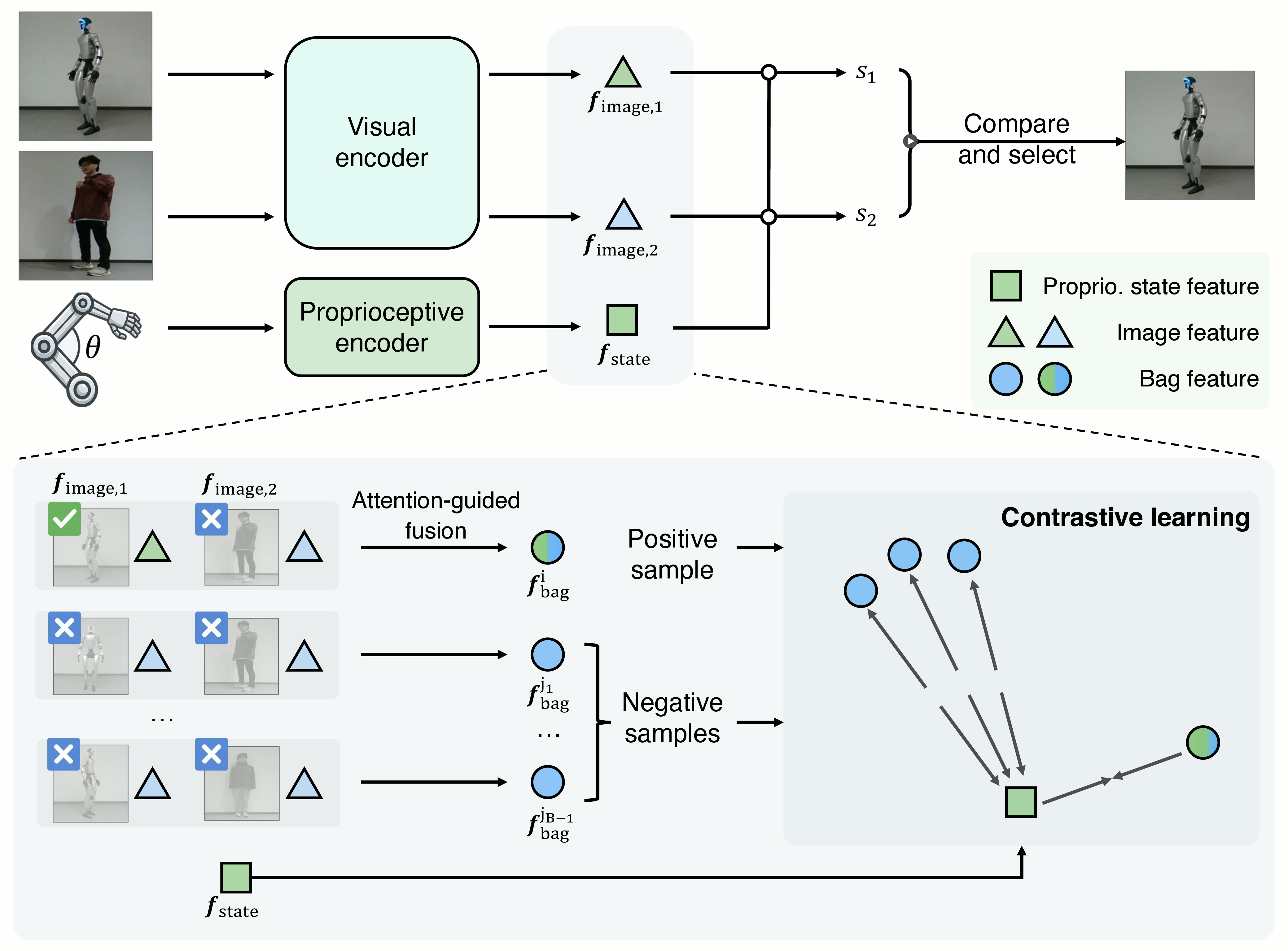
Self-other distinction
We use self-supervised contrastive learning to train our self-other distinction model, utilizing the intrinsic correspondence between proprioception and vision. Across diverse poses, our model consistently distinguishes self from others, selecting the robot, rather than the human distractor.
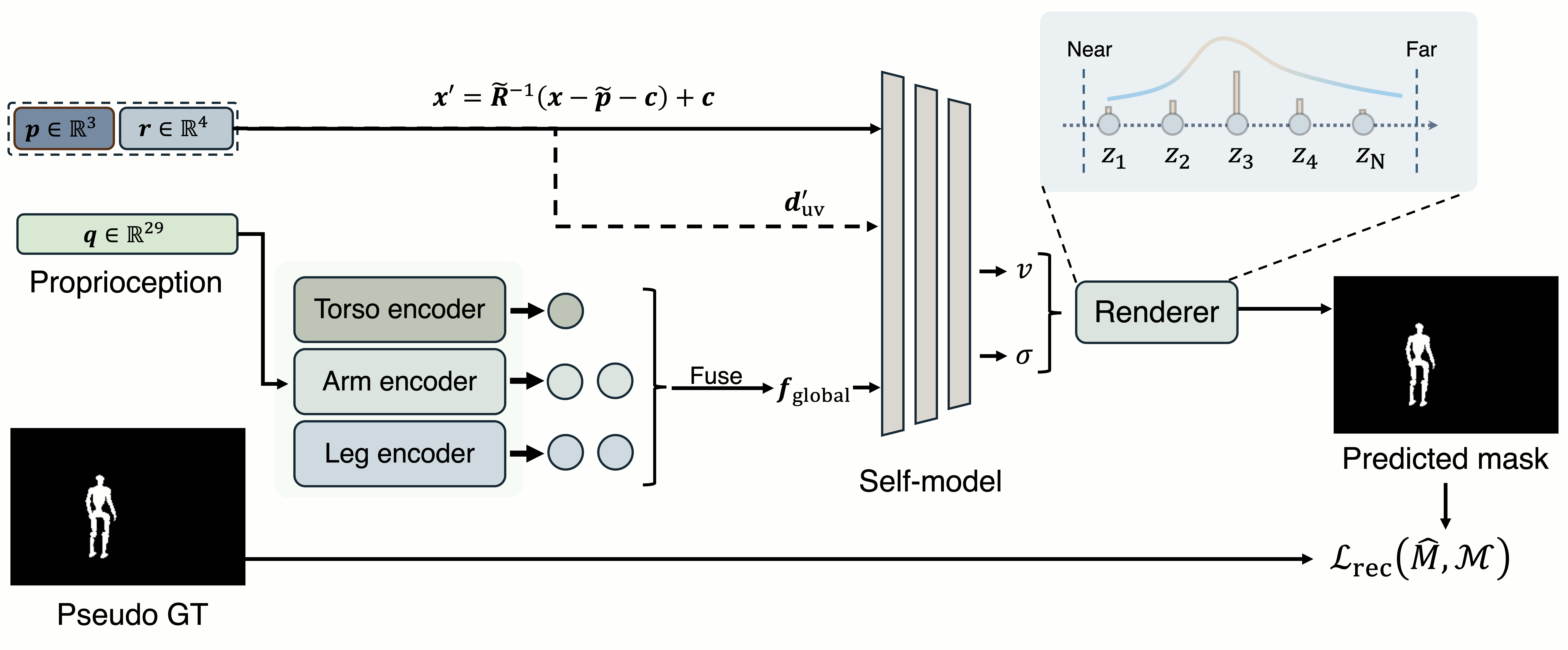
Self-modeling
Using the selected robot masks as supervision, we learn a self-model that predicts the 3D body occupancy field from proprioception. Our self-model produces coherent predictions. The visualized point cloud tracks the robot across poses, preserving the self-other boundary.
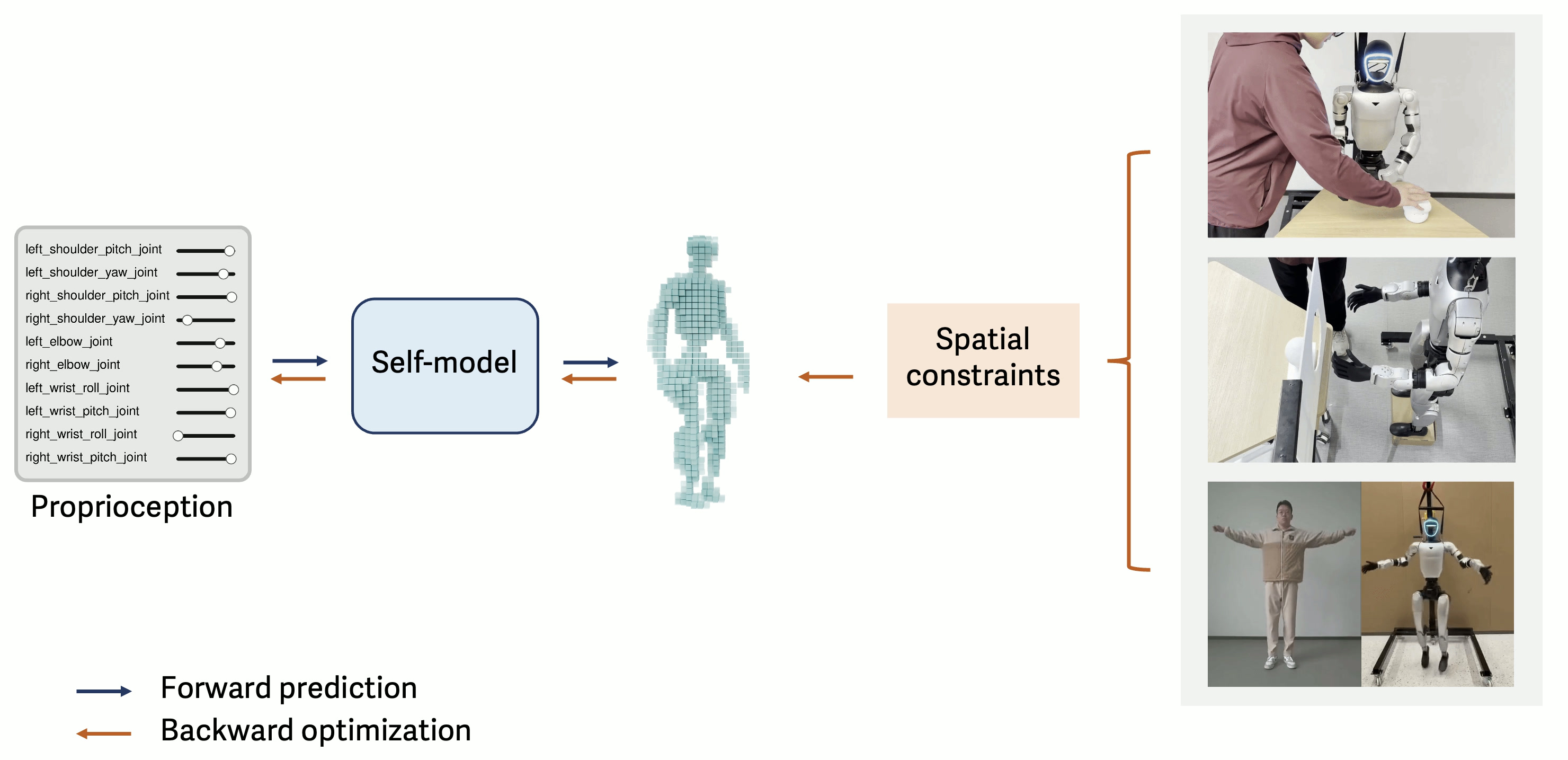
From self-model to physical interaction
Each real-world task can be cast as a spatial constraint on the robot’s body—a target to reach, an obstacle to avoid, or a demonstrated pose to imitate. Because the self-model provides a differentiable mapping from joint configurations to 3D body occupancy, these constraints translate into gradients over joint angles. We test this on three tasks: target reaching, collision-aware motion planning, and human-to-robot motion retargeting.
Target reaching
Side viewFront view
A human moves a night-light to different positions, and the robot optimizes its seven left-arm joint angles to bring the center of a hand-specific self-model to the target.
Collision-aware motion planning
Side viewFront view
The target is behind a board with a circular aperture, so a direct trajectory would collide. The robot uses learned body and hand occupancy inside a motion planner to find a collision-free path.
Human-to-robot motion retargeting
Human demonstrationRobot retargeting
Given a human demonstration, we extract 3D keypoints for body parts such as hands and feet, map them to robot-compatible targets, and optimize the 29 robot joints so that each predicted part reaches its target. The resulting robot joint sequence reproduces the human motion. The robot is externally supported as the self-model captures body geometry rather than physics.
Methods
Self-other distinction. Self-other distinction compares proprioceptive and visual embeddings, selects the self-mask, and trains the alignment with attention-guided contrastive learning.
Kinematics-free self-modeling. Kinematics-free self-modeling uses the selected self-mask to learn a pose-conditioned density and visibility field through bounded volumetric mask rendering.
Anypose-to-Anypose Point Track Policy Learned in Simulation
Video Generation and 4D Reconstruction as High-Level Planner
Generalizable Deployment to Diverse Real-World Tasks
Task-Agnostic Point Track Policy
Task-Agnostic Sim-to-Real via Anypose-to-Anypose
interactive viewer 🕹️
ToyFigure
We propose Anypose-to-Anypose (AP2AP), a task-agnostic sim-to-real learning formulation for dexterous manipulation. AP2AP abstracts manipulation as directly transforming an object from an arbitrary initial pose to an arbitrary target pose in 3D space, without assuming task-specific structure, predefined grasps, or motion primitives. Conditioned on point tracks, we train our AP2AP policy on over 3,000 objects in simulation, and directly deploy the learned policy to real-world dexterous manipulation tasks without any real-robot data collection or policy fine-tuning.
Paired Point Encoding
Comparison between our Paired Point Encoding with other representations. Point features encoded from our Paired Point Encoding keep correspondence and permutation-invariance of the current and target object points, which shows better performance for policy learning.
Teacher-Student Policy Learning
Overview of our Dex4D teacher and student network architectures. (a) We first learn a teacher policy via RL with privileged states and full points sampled on the whole object, leveraging our proposed Paired Point Encoding representation. (b) Given partial observation, i.e., robot proprioception, last action, and masked paired points, we distill from the teacher and learn a transformer-based student action world model that jointly predicts actions and future robot states.
Video Planner and Deployment
Video Generation & 4D Reconstruction as High-Level Planner
"Put the broccoli 🥦 on the plate 🍽."
Video Generation
↘️
Relative Depth Estimation
⬇️
Point Tracking
↙️
Object-Centric Target Point Tracks (interactive viewer 🕹️)
Aside from using video generation to extract target object point tracks, such point tracks can also be obtained from diverse data sources, such as one-shot human video demonstrations or 3D point cloud forecast models.
Real-Time Point Tracking
We also develop a real-time sparse point tracker on top of CoTracker for perception for test-time deployment. The tracker takes in the first frame of the generated video as well as the initially tracked query points, and tracks the object points in real-time during execution. The tracked points can be directly used by our Dex4D policy for closed-loop control.
Real-World Demo
Autonomous, 2x
Object Mesh Not Known Zero Real-Robot Demonstrations
Everything except the robot itself is unseen to the policy
Gallery
scroll down to see more ⬇️
Broccoli2Plate
LiftToy (Dino)
Pour
StackCup
InsertCarrot
Unplug
Meat2Bowl
InsertTennisBall
Carrot2Rabbit
Apple2Bowl
GrabFootball
LiftToy (Sloth)
LiftToy (Owl)
LiftToy (Rabbit)
Comparison with Motion Planning Baseline
Task: LiftToy
Ours ✅
Baseline ❌
The baseline is unaware of the hand and object grasping. Therefore the object would gradually fall off the hand during arm moving due to the lack of feedback. In contrast, our method has hand reactivity and learns to adjust or regrasp the object and proceeds with the task.
Task: Pour
Ours ✅
Baseline ❌
The baseline is very vulnerable to few and noisy visible points, while our method performs robustly even if there are less than 10 visible object points left due to extensive simulation training.
Generalization
Background & Camera
Distractors
Objects & Tasks
Perturbation
We demonstrate strong generalization to unseen object types and poses, backgrounds, camera views, task trajectories, and external disturbances.
BibTex
If you find our work useful in your research, please consider citing:
@article{kuang2026dex4d,
title={Dex4D: Task-Agnostic Point Track Policy for Sim-to-Real Dexterous Manipulation},
author={Kuang, Yuxuan and Park, Sungjae and Fragkiadaki, Katerina and Tulsiani, Shubham},
journal={arXiv preprint arXiv:2602.15828},
year={2026}
}